
Onwards to Umbraco 13 and Linux – Part 3
Having completed all of the underlying code for the backend of the site, first upgrading Umbraco and moving the database, before moving on to making the site’s custom functionality cross-platform compatible at the server side, attention moved now to the frontend of the site. When it comes to the site rendering, the differences between Umbraco 10 and 13 are minimal, so I could just have used all the views, CSS and JavaScript almost exactly as they were. However as this was an overhaul and you don’t get these chances often, I decided it was also going to be the best opportunity to improve both performance and the overall sustainability of the site, as these regularly go hand in hand (so if ever you have a stakeholder who is not convinced of the business case for one you can often convince them via the other). It’s this area that I’m focusing on in the final part of this short series, which also ends up being the longest so take a comfortable seat as I dive into optimising content, page structure/markup and JavaScript, and liberally throw about numbers and page scores all in the quest for maximum improvement for all (and if you’re a big lover of Google PageSpeed Insights, be prepared for some light scorn of the tool too!).
Part 1 – The Main Umbraco Upgrade
Part 2 – Making Custom Functionality Cross-Platform
Part 3 – Enhancing Sustainability and Performance
Part 3 – Enhancing Sustainability and Performance
The more bytes that are both stored and delivered over the net, the higher the carbon emissions required to do so, so one of the big things involved in this was always going to be reducing unnecessary data usage and this isn’t actually the first time I’ve looked at this. Back in January, I detailed some quick changes made around the generation of thumbnails on the site then, leveraging the fact I have a redirect rule present allowing me to easily change the querystring passed to ImageSharp sitewide. By altering this rule to generate them in the newer WEBP image format rather than the default JPEG that had already quickly resulted in a drop in download sizes. For fairness back then I’d measured the impact of this using the mobile scores on Google PageSpeed Insights, as these are always reported lower than the desktop score so have more room for improvement, and using Website Carbon Calculator on 2 key pages on the site. Firstly the Homepage, which somewhat atypically for most websites is small and has limited images and content present, and secondly a long listing page containing a lot of text content and images. By the end of that January run with only minimal changes I’d already gotten it to 63 (small) and 54 (large) for PageSpeed Insights, with Carbon Calculator ratings of A and B respectively. Now was the time to spend more time and introduce a greater level of improvement.
Optimising The Content
The first thing to look at was taking the WEBP image replacement further. As the name ‘thumbnails’ above may imply, there were lots of full-size JPEGs on the site to go with each of these too. Although not mentioned at the time, after that blog back in January, I’d briefly experimented with getting ImageSharp to regenerate these larger images on the fly in WEBP too. However even with the excellent caching it does internally and CloudFlare sat on top, the additional processing time needed for ‘cold’ images was still noticeable meaning any savings in filesize were lost to an appreciable time to regenerate the large image and have it render onscreen. So this idea was abandoned, and for the rebuild I decided instead to do this properly and re-encode all the existing JPEG images manually offline in advance. With 40,476 of these to work with, I was going to need some batch tool to do this. Enter again FFmpeg covered in the last post. Yes, once again the name misleads as it does an excellent job of encoding to static image formats as well as video. And so after about 2 hours, I had over 40,000 of them now updated to WEBP format instead leaving me next needing to get these into Umbraco. Getting them physically into the right place on the filesystem was done using PowerShell to search recursively through every subfolder in /media/ for a matching .jpg filename and then copy the .webp equivalent into the same folder. Always having used unique filenames for my images certainly paid dividends here, so it’s a good habit I’d strongly encourage every content editor or creator to try and get into as even if not needed now you never know when it may come in useful in the future.
Recursively copying files to folders based on matching filenames using PowerShell:-
$source=get-childitem -Path $inputFolder | Where-Object {$_.MODE -NOTLIKE "d*"}
$TARGET=GET-CHILDITEM -Recurse -Path $outputFolder | Where-Object {$_.MODE -NOTLIKE "d*"}
$counter = 0
foreach ($file in $source)
{
$matched = 0
foreach ($destination_file in $TARGET)
{
if ($destination_file.name.Replace(".jpg", ".webp") -eq $file.name)
{
$counter += 1
$matched = 1
write-host Match found $file.name
Write-host Source $file.PSPath -ForegroundColor Green
write-host Destination $destination_file.PSParentPath -ForegroundColor Yellow
copy-item $file.PSPath $destination_file.PSParentPath -Recurse -Force
}
}
if ($matched -eq 0)
{
write-host No match found $file.name -ForegroundColor Red
}
}
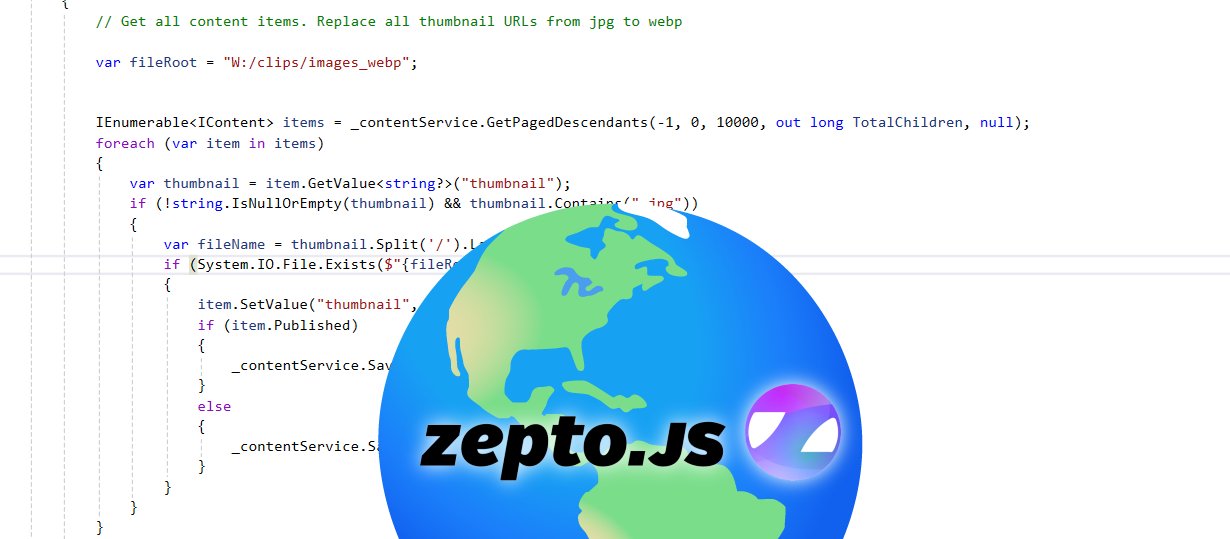
With the image files physically in place, I then had to get what was stored inside Umbraco’s database to now reference these new files on the filesystem rather than the original JPEGs. To handle this I turned to Umbraco’s ContentService and MediaService handlers which have been available for a long time and allow for updating content and media respectively. An Umbraco migration was created to iterate through every node in the media library. Where a media item contained a reference to a .jpg file then a check for a matching physical file with a .webp extension was performed. If one existed, a simple text replacement of the value stored for the URL was made to the media item. In most cases ‘File Size’ and ‘Type’ were empty, presumably as this had come from an older Umbraco 7 instance originally, and these are not essential for anything to work in the CMS. But for completeness-sake, where these did have values present I would also update these with the new calculated size and format values too. Media nodes done, in most cases content nodes would use pickers to point to the item from the media library so this would have been covered. However, I have used some direct upload fields within Umbraco historically too, so to cover these I had to repeat the same operation on the content tree via ContentService, with the only difference being the need to perform a publish whereas media changes take effect immediately on save. As publishing was involved, I had to make sure to remove all the custom publish and save hooks I mentioned I’d set up in the last blog post for the duration of this migration run of course! It is possible to disable the firing of notifications via code, but for a run-once operation I was fully in control of just commenting out the affected code sufficed for me.
Throwaway C# Umbraco Migration to update URLs via MediaService & ContentService:-
protected override void Migrate()
{
// Get all content items. Replace all thumbnail URLs from jpg to webp
var fileRoot = "W:/clips/images_webp";
IEnumerable<IContent> items = _contentService.GetPagedDescendants(-1, 0, 10000, out long TotalChildren, null);
foreach (var item in items)
{
var thumbnail = item.GetValue<string?>("thumbnail");
if (!string.IsNullOrEmpty(thumbnail) && thumbnail.Contains(".jpg"))
{
var fileName = thumbnail.Split('/').Last().Replace(".jpg", ".webp");
if (System.IO.File.Exists($"{fileRoot}/{fileName}"))
{
item.SetValue("thumbnail", thumbnail.Replace(".jpg", ".webp"));
if (item.Published)
{
_contentService.SaveAndPublish(item);
}
else
{
_contentService.Save(item);
}
}
}
}
// Get all media items. Replace all thumbnail URLs from jpg to webp
IEnumerable<IMedia> mediaItems = _mediaService.GetPagedDescendants(-1, 0, 80000, out long TotalMedia, null);
foreach (var item in mediaItems)
{
var thumbnailValue = item.GetValue<string?>("umbracoFile");
if (thumbnailValue != null && thumbnailValue.Contains(".jpg"))
{
var thumbnail = JsonSerializer.Deserialize<JsonElement>(item.GetValue<string>("umbracoFile"));
var fileName = ((string)thumbnail.GetProperty("src").ToString().Split('/').Last().Replace(".jpg", ".webp"));
if (System.IO.File.Exists($"{fileRoot}/{fileName}"))
{
var oldSize = item.GetValue<int?>("umbracoBytes");
var oldExtension = item.GetValue<string?>("umbracoExtension");
item.SetValue("umbracoFile", thumbnailValue.Replace(".jpg", ".webp"));
if (!string.IsNullOrEmpty(oldExtension))
{
item.SetValue("umbracoExtension", "webp");
}
if (oldSize != null && oldSize > 0)
{
item.SetValue("umbracoBytes", new System.IO.FileInfo($"{fileRoot}/{fileName}").Length);
}
_mediaService.Save(item);
}
}
}
}
While it may not be recommended as best practice to do simple text replacements of URLs inside Umbraco like this and you’d probably be recommended to fully reupload the file, this approach did work fine and meant I now had a media and content library with all of the images migrated over to WEBP. Or 99% of them anyway. There’ll likely be a few stragglers pop up where I’d uploaded something nonstandard at the time, but these will be so few in number I can either safely ignore them or manually swap them out later if spotted. The overall reduction on this took the stored images from 3.45GB to 1.2GB, or a reduction of about 65%. That 65% reduction is particularly important as a similar percentage reduction should follow through to all data transfer from servers to end users.
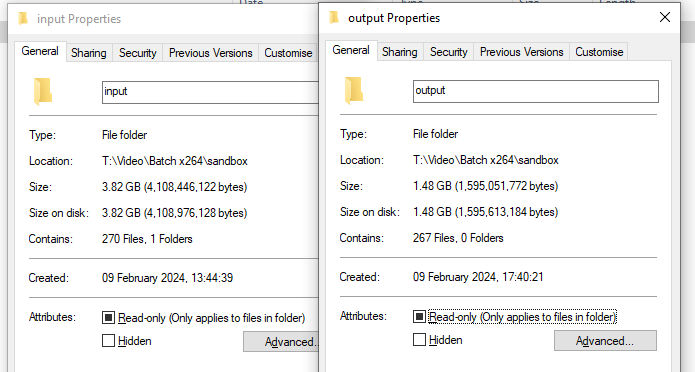
Even bigger than the images though with a site like this was the video content involved. By its very nature, video was always going to be a much harder element to reduce than images, but I was determined to see what could be done here too. With over 6000 of these, it was going to be impossible to tackle all of them, so I decided instead to focus on those which would have the biggest impact from an emissions point of view. For me, this meant looking at any video file over 10MB and seeing how much they could be brought down by, resulting in a topslice of about 260 video files. Historically I’d always tried to keep video at a very good quality on the site relative to internet connections of that time, bearing in mind I have been running this site 23 years now, since those pre-walled-garden-YouTube days when many people were still using Dial-Up Internet. However, observation of user behaviour in recent years has led me to conclude people are much more concerned with quantity and convenience than quality. Which is why you’ll happily see people sharing YouTube videos of someone pointing a phone at a clip of The Simpsons from their TV rather than seeking out a proper copy of the video, listening to previously high-quality stereo FM radio stations in much lower-quality mono on DAB/DAB+ while the owners make double the profit from having two lower-quality stations, or not even bother switching their TV to the HD version of ITV1 as it involves remembering 2 more digits on their remote and they ‘can’t tell the difference anyway’ between that and the standard definition version. So I decided to softly exploit this same user behaviour somewhat by re-encoding anything over 10MB in size just with a lower bitrate, and a much tighter constraint set on ‘peak’ bitrate values. Video encoding tries to flex up and down the underlying bitrate to provide more bits to ‘busier’ scenes. But this can also mean if you get something with a lot of fast-moving small details like fireworks or leafy trees they can cause quite dramatic spikes in size without these tighter controls in place.
Getting these updated videos back into the media library was simpler than it had been with the images. As there was no change to the underlying video format or filename this time, I was able to just use a similar PowerShell script to find and replace the matching files directly on the filesystem, without needing to change anything in Umbraco itself. I also did one last run of my old scripted way of generating HLS chunks to ensure these had all been regenerated based off the newer smaller files too. If you were to closely compare the re-encoded videos to the originals side-by-side, it would be possible to tell the difference, however to most casual viewers the difference is not noticeable. The reduction in size is more marked though. Reducing 3.82GB of video to 1.45GB, or coincidentally about 60% reduction again. As this is only a slice of the total video stored for the site it’s a little harder to say how much of this will flow through to the overall end-user data transfer as that will depend on exactly what they open. But it will have an impact on the videos that make the most difference, and there is nothing to say I cannot extend this further in the future. As I was not just looking at the historic site content though and considering how these reductions can continue in the future, I’ve updated all my internal workflows to ensure all new video that is created locally will be encoded using these new settings and any new images are generated straight to WEBP format ready for upload.
Optimising The Frontend Build
With all the reductions in place to content stored within the site, everything else involved now was improvements to the frontend. In an ideal world, it would have been nice to have started this again completely from scratch using much more modern approaches and a clean slate. However realistically it would also then have meant the project likely never getting finished, so improving the existing frontend was definitely going to be the order of the day. Yes, if ever you get disheartened when working on external websites, just remember the same issue anyone who’s ever worked on any client website will have run into still applies to personal projects. The starting point for this, as with my brief blog in January, was to look at Google PageSpeed Insights (and as much as Google has tried to distance its name from it these days, I still refer to it as such). I could have used Lighthouse in Chrome for this too, but they largely indicate the same things and I’ve always used the website instead. I will at this point reiterate my usual point about taking everything listed on there with a large pinch of salt though as it requires interpretation and understanding of how everything fits into your own unique solution. And despite what SEO ‘specialists’ may say, not implementing every big red alert on the results page and still having some scores below 100 will not drop you ‘a million places in The Googles’, nor do they necessarily mean your site is performing badly. Results from this tool are also notoriously inconsistent, with scores regularly fluctuating from low to high from one run to the next without even changing anything, so if depending on it make sure to run it a few times with gaps in-between or cache-busting querystrings due to result caching. But as long as you fully understand its limitations, when it is used as a starting point for listing general guidance and ideas that you can pick and choose to experiment with it can be an excellent resource.
Based off the top recommendations from here, I first improved the Webfont loading by moving the Google Fonts CSS locally in the project rather than relying on their remote CSS. The historical argument behind using remotely hosted assets like JS and CSS was that it allowed everyone else using these to be sharing the same browser cached versions, but in a lot of modern browsers they now isolate this down to different versions for individual websites anyway to prevent cross-site tracking. So the remote argument has been weakened massively, and in addition you’re introducing a risk with remote assets if that remote server outside your control ever gets compromised. Hosting this locally also allowed me to remove lots of redundant character sets I know my website won’t ever use as well as tweak the font-display: swap CSS settings so the page can render with a default font before it has even fully loaded, though it’s rare this will be seen. The next biggest thing PageSpeed Insights insisted I should remove was all the JavaScript and CSS for the video player as it was ‘unused’, proving my point about not just trusting everything it says as I’m quite sure I know the video player is an integral part of a site with a lot of video on. Instead, I optimised this by only not loading this on pages I know will never have the video player such as the homepage, and then just disregarded their red warning flags on others. I then replaced a small number of PNG images used in the scaffolding of site design with lossless WEBP images too, as WEBP is capable of both lossy and lossless formats so can be used to replace both JPEGs and PNGs. While this was only a 20k saving which is a tiny improvement relative to all the main image content changes above, every little helps when it comes to performance and sustainability improvements. As for those other lossy content-based WEBP thumbnails, they were all changed in the markup to be lazy loaded using the HTML5 native ‘loading=”lazy”‘ attribute on the < img > tags. This is a quick and simple way to add an indicator which improves loading speed and reduces unnecessary offscreen image downloads in all modern browsers, without having to resort to slower or bloated JavaScript libraries like we did in the past. Finally, I also took the opportunity to look over my own CSS file and remove any redundant style rules I could find which I knew were no longer in use. Again this only yielded a tiny improvement in size, but this one is not just about size. Having fewer styles also reduces the amount of parsing the browser has to do of the CSS on render, and the less processing work a browser has to do the faster it can render and again the lower the carbon emissions.
After all that, the work the browser has to do on the parsing and rendering stages for JavaScript was the biggest remaining performance issue showing up on Page Insights for this. I’m still a firm user of jQuery, for all I know it’s definitely fallen out of vogue these days with a lot of front end developers. On this site I wouldn’t say I’d used it extensively, but I’d used it and some third-party plugins which depended on it ‘enough’ for it to not be trivial to remove completely. So instead I looked at switching it out for a lighter replacement framework. There are many purported ‘jquery-syntax-compatible’ libraries out there that aim to replicate subsets of the overall framework (some with hideously ungooglable names like ‘Cash’). However, whether these will work or not for individual cases depends on exactly which features you’ve used, in particular often missing the Ajax and animation parts of jQuery. As the jQuery modal popup plugin I use already mentioned in their readme it had been tested as compatible with one of these, namely ‘Zepto.js‘, I decided to start with this one as a base and then patch in anything else needed. With Zepto, most of my existing jQuery code worked without changes. The most I had to add was animation support which involved recompiling my own Zepto JS file via a local copy of node, and then an extension to replicate the SlideUp/SlideDown/SlideToggle methods available in jQuery full, as attempts to get these working the same via standard CSS3 transitions eluded me. With that changed over, there were only two remaining incompatible jQuery plugins I was using for the site that wouldn’t immediately work with Zepto. One was MatchHeight, normally used for ensuring content blocks are the same height, and the other was Jquery History, needed for legacy browser support when accessing the browser history API. This is where real understanding of your own individual solutions becomes key. MatchHeight was only being used in a single place in the footer, something I quickly established I could easily resolve with only a few lines of simple CSS, and Jquery History wasn’t needed for any browser beyond IE11, which I’d already decided I wasn’t too worried about supporting with the move to WEBP images. So after all of this not only had I been able to replace Jquery with a much lighter equivalent, I had been able to remove several unused plugins some of which even Page Insights had failed to pick up as ‘unused’ (if you’re not following, I must have stacked up enough pinches of salt with this tool by now to supply a small chip shop for a week). With all these in place, the overall mobile scores had gone from 63 to 74 on the homepage and 54 to 80 on the larger page – yes surprisingly the larger page actually saw a bigger score increase, which I can only really attribute to the much higher number of images now being lazy loaded. These were results I was very happy with. As for the knock-on impact this had with the Carbon Calculator rating too, the homepage had now gone from an A (0.14g CO2) to an A+ (0.08g CO2), and the large listing page from B (0.28g CO2) to A (0.14g CO2).
Away from performance improvements, one little niggling Insights score that still bothered me was around Accessibility. From a technical point of view, I’ve already made a lot of effort to have the code as compliant to the WCAG standards as possible, such that I’d already gotten it to a 98 score on most pages under the limits you get with automated testing. I know from similar reporting in the WebAIM tool that the remaining ‘2’ shortfall stemmed from some gaps in the header tag ordering, which WCAG recommendations are should always go in order from h1 > h6 for the benefit of screenreaders. By changing the structure of some of the title tags around, I was able to get this score up to 100 on most pages. However, this is also where the importance of understanding how to interpret a recommendation and not relying solely on matching automated testing for accessibility comes into play. Some of the pages that still ‘only’ score a 98 do so because there is no valid h2 I could put in so I go straight to using h3. The h2 subtitles on my site are normally used for grouping related content together, but sometimes there is simply no subgrouping needed as the main h1 page title is enough. If I had wanted to solely tick the boxes and gain that arbitrary ‘perfect’ score I would have either had to have a subtitle that just repeated the main title, or have a situation where later titles would be inconsistently presented as h3 on some pages but on others be upgraded to h2, despite representing the same thing across all. Doing either of these to me seemed more detrimental to any actual user from an accessibility point of view and the focus should always be on how it benefits the users not meeting an arbitrary score. And so this was another occasion where it made more sense to ignore Page Insights, with the result being code that is marked as structured better than it was before on most but not all pages. But it is important to stress that this is just the crude automated testing of code, and I know there is still much more work to be done on this to test it with manual testing and real user tools, which is something I already have marked in as a future improvement project of its own.
Optimising The Infrastructure
With all those code improvements in place, and as much as possible in place, I launched the site on my OracleCloud VM Linux hosting on February 26th. There were a couple of initial small hiccups with URLs from external sites and the Linux server not actually permitting new uploads to back office bigger than 1MB, but these were quickly resolved and then everything was left to run smoothly for a week, during which time the existing Windows and Umbraco 10 solution remained in place so I could still switch DNS back to it at short notice if needed. Once I was confident this was not going to be needed though, it was then that I could do some final infrastructure tidying to further improve the overall sustainability of the solution. Previously the hosting was split across three places:-
- A ‘Main’ in-house Windows machine, serving the main webpages and all images out of Umbraco and the back office for this, my biggest site. This server also hosts my other smaller sites (like this blog) and email, as well as some mini servers I use internally and already has redundant internet connectivity.
- An OracleCloud Linux VM, serving only the video content for this site.
- A ‘Secondary’ in-house Windows machine I have in another external location, which contains a backup of a lot of personal files, as well as mirroring all my sites and email so I could swap DNS to this in the event of the main server or its connections failing.
Yes, I’m aware this was already massively overengineered for a set of non-profit and personal data uses, and more than I know many businesses who depend on their sites or internal files for income will often have in place. But ultimately I’m still a techie at heart, so you can’t really fault me for this! These were all kept in sync by pushing relevant files out to the Linux server on publish, and by then syncing the two Windows servers up overnight.
With the new site consolidating all the hosting of Umbraco onto the remote Linux cloud instance, the Main Windows server was now repurposed as only a fallback for this main site to be used in emergencies, and its other smaller tasks which the public doesn’t see. When it’s already now a backup a lot of the time, suddenly having yet another Windows machine as a backup to that was even less important, as the likelihood of two servers going down and me having to swap to the now tertiary server was getting ridiculously low. I still need it there as an offsite file backup (your data is valuable and still irreplaceable by insurance people, so have regular backups!) and an absolute last-case emergency server, but I started looking at ways to reduce the time it was actually powered up to only an hour overnight in order to copy up-to-date backup files across. For the remaining 23 hours, I’d initially looked at just putting the machine to sleep. But some missing video drivers (which are apparently needed for sleep to be an option) and limited support for remote WakeOnLAN when outside of the network limited this. So instead I went back to using some Smart Plugs, several of which I’ve had sat unused for a long time after I worked out they were still using around 1w to keep them on the network even when doing nothing else. The mini PCs I use for servers were always quite efficient anyway, averaging around 10w most of the time. But this setup allows me to now have the tertiary server only using 10w for that 1 hour overnight while updating files, before powering down the plug so it effectively only uses 1w for the other 23 hours, taking me from approximately 240w/day to 33w/day. And if I ever do need to use it in an emergency I can still easily issue a power on command to the smart plug outside of the regular schedule with the machine BIOS set up to automatically start whenever power to the plug is restored. While these may not seem like big figures, multiplied up over the course of a year this should result in a power consumption reduction from around 87kWh to 12kWh. That’s a 75kWh reduction, equivalent to around 19.5kg of CO2 across the course of the year using the average figure of 0.26kg/kWh I’ve referenced before for the UK (source: https://ourworldindata.org/energy ). Hooray for more carbon reduction!

Concluding on a High
It’s difficult to calculate exactly the total impact all the sustainability and performance improvements made from this project will have, but to summarise all the headline statistics I can again:-
- 2.2GB reduction in image storage space, resulting in 60% reduction in data transfer
- 2.4GB reduction in video storage space from the top 10% of files
- PageSpeed Insights score increases of 11 and 26 across two sampled pages
- Website Carbon calculator rating improvements to A+ and A with a reduction of approx 50% CO2 produced across the two sampled pages
- Infrastructure reductions of around 75kWh/year energy usage or 19.5kg CO2
And all of this while seeing faster load and rendering times and no noticeable detrimental impact to what an end user on the site would see. By itself, this whole project is not going to be enough to save the planet, and it’s likely not something that will be noticed by most casual visitors. But it’s an achievement I feel I should take some pride in and would urge others to do the same with their projects. And if there is anything you would like to see me expand upon further do get in touch via Twitter or Mastodon as if sharing information can help encourage anyone else to look at similar ways they can make improvements, who knows what a greater collective impact we can make!

2 thoughts on “Onwards to Umbraco 13 and Linux – Part 3”
Comments are closed.