
An Early Look at Umbraco 12 Content Delivery API

Disclaimer: This blog post contains pre-release functionality, all subject to change before final release, and some of my interpretations of what is there may be wrong.
Background
For those who’ve been around in development a few years, people may remember ‘headless’ (effectively separating the frontend application from the backend data) being a huge buzzphrase a few years back – by which I mean it was still in that phase where clients would be sending it in their requests, but when asked why they were looking for it as a requirement didn’t actually know they’d just heard someone else say the term so thought they needed it. Thankfully these days though the concept has matured a bit more and slipped more into proper use, so it tends to now be used more where it makes sense rather than just because it sounds good. Umbraco has had a headless solution available as part of their Heartcore cloud product for some time now, but it remains heavily integrated into the whole cloud platform infrastructure there so to build it into a traditional site based on the core CMS product has hitherto had to rely on third party extensions.
This is all set to change starting from Umbraco 12, with an API designed to expose the content tree in JSON coming to the core product, tentatively in June 2023. This is actually quite a big feature for Umbraco, however unfortunately it’s often ended up overshadowed a bit due to the even bigger change for the new back office for the Umbraco 13 Long Term Support version due later this year. Update: 2/5/2023 – Now pushed back to the non-LTS Umbraco 14 in Summer 2024.
At the moment we have a small project using a headless approach, which used the UmbracoContentAPI package to expose content in JSON for our frontend to render into a site. This package was originally built for v9 and has continued to work fine into v10 LTS without any updates. However we are about to roll out a massive extension to this headless site over the next few months integrating lots of new components. So with the impending release of a core headless API, I thought it was prudent to see how develop-able against this things are already as it’d make more sense to do a big uplift of development against what is going to be the core solution for potentially several years rather than something older. Some early demos of the new Core API were shown at a talk at Umbraco Spark in early March, from which I’d also gotten the tentative dates of a release candidate for v12 being due May 17th with the final release due June 29th. For the sakes of exploration this early though I needed to be in even before that RC date, which meant the rare decision to dig into the source code directly.
This is where the main bit of this blog post comes in. It’s a brief look at some of what looks set to come as seen in this early pre-pre-release version.
It should go without saying of course, but I will still say it again, is that as this is a version not yet officially released, many things may change and features may be added or removed completely ahead of the official releases. Everything here should be considered just a flavour for how things are currently.
Getting into the code
After checking out the Umbraco source code from the Umbraco CMS GitHub repo, and switching across to the v12-dev branch, the first thing to catch my eye was that a big pull request of a feature branch called ‘v12/feature/headless’ had been merged in on April 19th, or barely a week before this exploration bringing a huge number of tickets with it. This possibly suggests the biggest part of the work is already in place now, and also probably means I’d timed looking at this quite well. It’s been a while since I’ve been in the Umbraco source code directly, so it took a bit of fiddling to get reacquainted and running, but thankfully getting the source building and running is quite well documented inside their repo too. Indeed I think the hardest part I ran into is we still use a very old version of Node for compatibility with some ancient projects, so in order to get the frontend building I had to manually switch the project folder over to using Node 14 (Tip – NVS rather than NVM is very useful for doing this on a per-project basis in Windows by the way). After sorting that so the frontend of their projects could build, and attaching a connection string to appsettings.json in the supplied Umbraco.Web.UI demo project to an existing Umbraco 10 database, I was able to fire up Visual Studio in debug mode and get it into the v12 back office. Or… almost. It would go through the upgrade process and then throw an System.IO exception at the very end complaining about ‘Umbraco.Web.UI\umbraco\Data\TEMP\NuCache’. However this was easily resolved just by creating the NuCache subfolder in that location manually, and after that everything ran fine.
So everything was running now to back office, but… how do you actually use the new headless API, at some point renamed ‘Content Delivery API’ according to the above commits? We’d seen demos of it at Spark, but I don’t know about you but I certainly can’t remember endpoints seen on slides from over a month ago that well! Thankfully though even the documention is quite well into production even at this early a stage, so it looks like we should have some good docs in place for launch. The Umbraco Docs are also maintained on GitHub in the UmbracoDocs repo, with a branch named ‘cms/delivery-api’ already containing a handy Content-Delivery-API page to get you started. As this page or branch is highly likely to change I won’t include a direct link here, but you can find it via the main repo above. Formatting-wise this was a bit fiddly to follow as the markdown for swagger wasn’t rendering out with formatting in GitHub and I hadn’t pulled it all down locally, but there was enough here to be able to work out the general structure of the new APIs, and actually try out a few endpoints.
All URLs currently seem to hang off a base address of:-/umbraco/delivery/api/v1/content/xyz
with various paths and querystrings then built on top.
The most obvious of these to try first was the ‘get all’ version sitting on the root:-
/umbraco/delivery/api/v1/content/
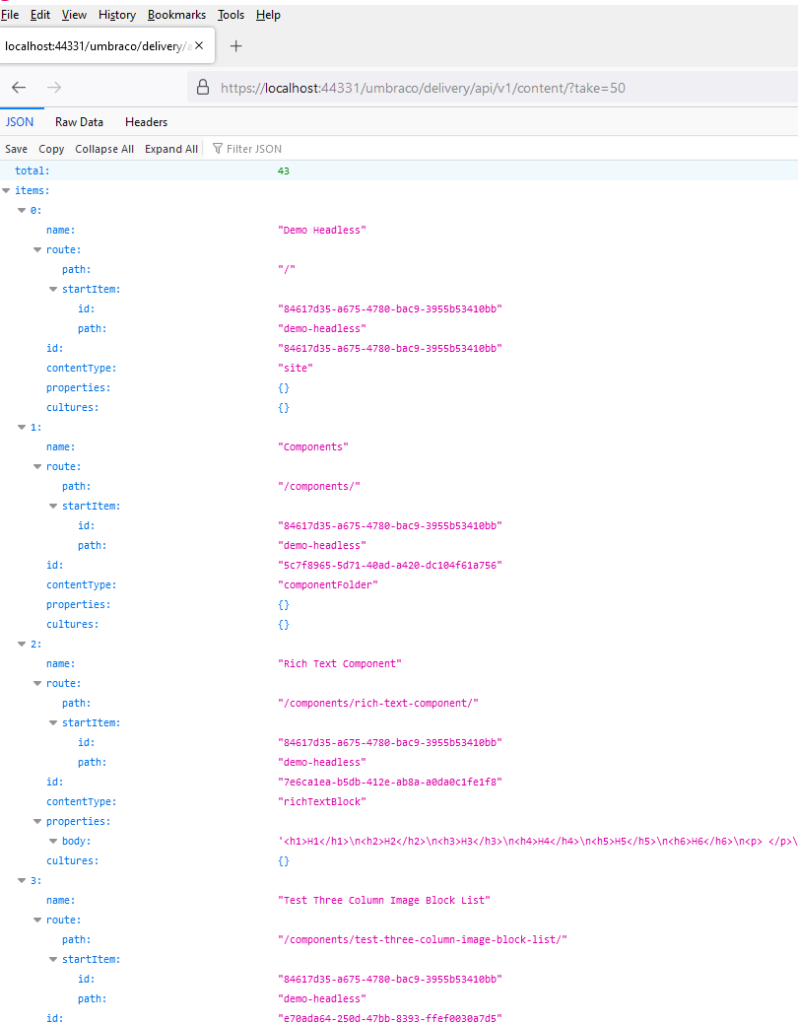
By default this returned a block of JSON showing 10 items intended for paging, but you can expand it with a querystring ?take=x to get more in one go. This worked fine for getting me all of my content tree back in a nice JSON format (apologies for this being in image only format, but it’s only to illustrate a blob of JSON):-
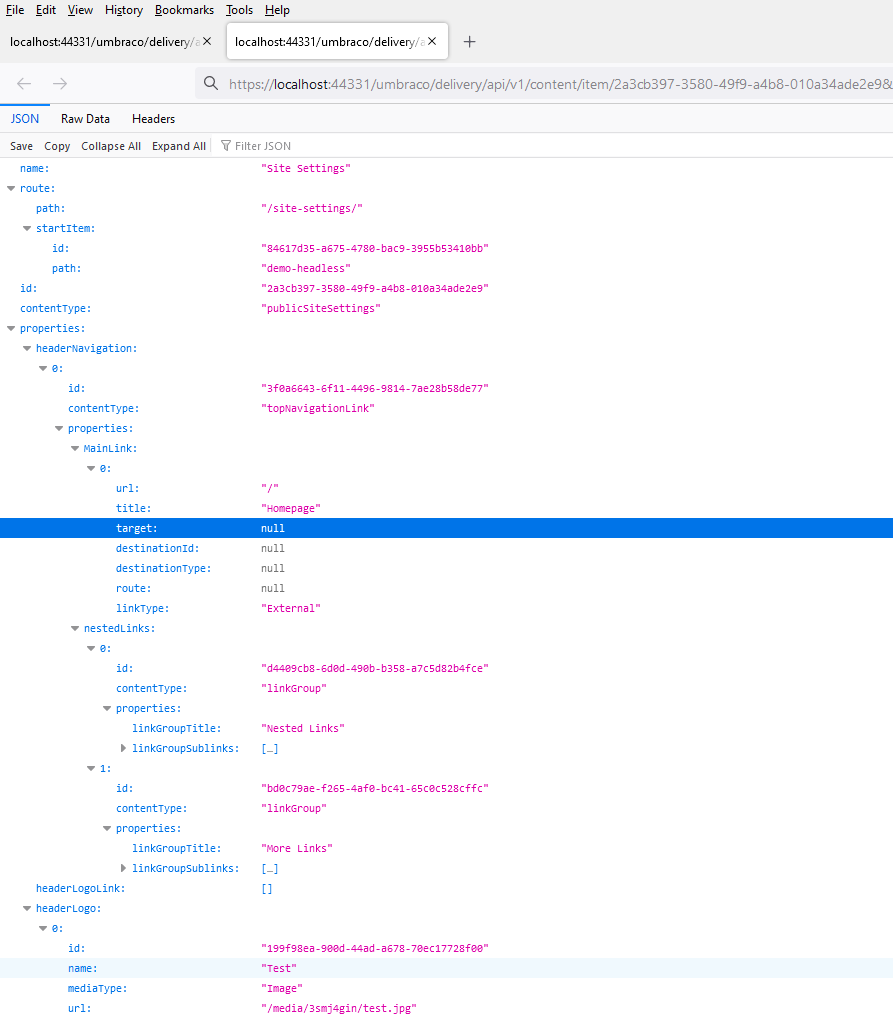
After that the other most obvious next endpoints to try were to get single nodes of content. This is supposed to be possible by both ID (guid rather than the legacy int) and path of the node, though in the time I had for this brief dive I failed to get path working and only managed to get it by GUID:-
Conclusion
What is there is looking good, even at this early a stage and going off what was a very brief dive for now. It was mentioned at Spark that what is coming in 12 isn’t likely to be everything in the Content API and that other things will follow and enhance it in minor releases, but certainly a huge amount of the core functionality is looking to be there, and I’d expect by even the RC in May it’ll be enough to begin developing against ahead of the final release. I’d expect many more details to be revealed nearer the time too – for one thing there’s currently a ‘Current Limitations’ section in the docs which still has the ‘TBD’ note against it!
Some other things I did spot in the pre-pre-release docs which may also give an idea of the sorts of things that may be planned, whether for initial release or to come later:-
- There will be facilities for excluding certain templates via your main project config, so you can configure it centrally to avoid accidental exposure of more sensitive back office content
- The ability to have private keys for content is being planned in. So content can be exposed fully publicly via the API, or only shown if a key is sent with the request
- Following on from this, it looks like the plan is to be able to expose preview content too. So potentially a private key could be used here and the public only see the published docs
- When pulling in a node, options to automatically expand and pull in the content from related pickers are included in the endpoint. I wasn’t able to get this working in my short tests, but it looks like this should either be possible to expand ‘all’ properties or just choose specific properties to expand
So yes, exciting times ahead! And as an added plus, I now have a lot more idea on getting the source code for Umbraco building locally. Something which is potentially going to be much more useful from the summer onwards when I’m hoping to have more time and energy to actually contribute things back too!
